One of the most common problems in student essays is not lack of knowledge, but lack of a clear argument. In biological anthropology, strong essays do more than describe variation or summarise readings. They explain patterns using evolutionary, ecological, and biocultural theory.
This guide is designed to help students write effective thesis statements by showing:
what counts as an argument in biological anthropology,
how to place the thesis within a clear introduction structure, and
how to use signposting to map out the body of the essay.
The guide is available as a downloadable PDF and is distributed under a Creative Commons licence, allowing it to be shared, reused, and adapted for teaching purposes with appropriate attribution.
I am thrilled to report that I was finally able to continue my research in Indonesia. My previous fieldwork was pre-Covid (2018 to be exact). Over the past few months, I did fieldwork for 7 weeks in November/December 2023 and another 2.5 weeks in February/March 2024.
So happy to be back doing the second round of data collection for the ENDOW Project — a collaborative, longitudinal project looking at the effect of social networks on wealth inequality.
Together with an amazing team of local collaborators and assistants, I collected the necessary data for this project, as well as data for two additional projects, including one that is a continuation of research I did as part of my PhD research. I wore my University of Washington (PhD 2006) hat to reflect my heritage.
The fieldwork was done in cooperation with the Department of Anthropology, Universitas Sumatera Utara (USU) in Medan, Indonesia. I was lucky enough to be invited to give a public lecture about my research in Indonesia — starting with my PhD research until now. I was absolutely thrilled with the level of engagement the students from USU showed. Can’t wait to go back again!
One consequence of the pandemic over the last few years is that field researchers such as myself have found it difficult to keep our research programs on a forward trajectory. I wrote a short piece for the school’s annual magazine about finding a research object right under my own nose.
“As anthropologists, we ply our trade by seeking insights on the lives of others, and sometimes ourselves, in far-off locales. This makes it easy to overlook the lessons to be learned from local sources. I was writing a chapter on what evolutionary theory can tell us about parenting and technology. Seeking apt illustrations for each example, I rummaged personal (Figure A) and open-access images. One of my case studies was the cultural evolution of baby bottles. The earliest were from Ancient Rome, but the only images I could find would have saddled me with hefty publishing fees.
What could I do?
My initial solution was to use something more recent—a porcelain bottle from 19th Century Japan. Then, as I walked to my classroom in AD Hope (miss that place!), something caught my eye. In one of the ANU Classics Museum’s cabinets was something that looked like the baby bottle of my desire. It’s label confirmed my suspicion and, just like that, I had the perfect image of one of the earliest infant-feeding vessels (Figure B). It was a timely lesson. The pandemic lockdowns and resultant fieldwork bans have meant that most of our research has had to focus on things that are right here under our noses.
Although these events occurred a couple years back (“the pandemic slowed down publishing,” my editors told me) the book was published in October 2021:
Kushnick G (2021). The cradle of humankind: Evolutionary approaches to technology and parenting. In: Weekes-Shackelford VA, Shackelford TK (eds.), The Oxford Handbook of Evolutionary Psychology and Parenting (pp. 115-134). Oxford University Press.”
This post relates to a paper I recently wrote and posted on PsyArXiv.
Karo couple from North Sumatra, Indonesia. I previously conducted Fulbright Scholars Research on impal marriage amongst the Karo.
A pairbond is a close and enduring relationship between two individuals. It often includes mating and, in the case of humans, marriage and shared childcare responsibilities. There might be a tendency to think of pairbonding as unique to monogamy, but an individual can develop a bond with more than one individual in polygamous systems as well.
At some point in our recent evolutionary past, our ancestors began to pairbond, which differentiated us from our closest living relative the chimpanzee who engages is much more promiscuous mating. The evolution of pairbonding then had wide-ranging effects in shaping various aspects of our behaviour, anatomy, physiology, and society.
Evolutionary scholars interested in human behaviour have approached the problem in a variety of ways — so, in a nutshell:
Human behavioural ecologists analyse the adaptiveness of human behaviour in social and ecological context.
Evolutionary psychologists study the evolution of the behaviour-producing mechanisms in past environments.
Dual inheritance theorists are concerned with cultural evolutionary processes, including how biology and culture coevolve.
I wrote a paper that investigates how these paradigms have tackled the problem of pairbonding. For each, I examined two questions that have been addressed by their practitioners (see table below). In doing so, I was able to assess the viability of three pathways that have been proposed for integrating the methods and assumptions of each paradigm.
Paradigm
Question 1
Question 2
Human Behavioral Ecology
When will a woman marry an already married man?
What ecological factors are associated with pairbond stability?
Evolutionary Psychology
How do short- and long-term mating preferences compare?
Do sex differences in jealousy reflect our evolutionary history as a pairbonded species?
Dual Inheritance Theory
What cultural factors have led to the primacy of monogamy in Western societies?
Can cultural evolutionary forces lead to variations on the normal pattern of pairbonding?
Some background: First, I am a human behavioural ecologist at The Australian National University (ANU) with interests in human reproductive strategies. Second, my PhD supervisor was Eric Alden Smith, who wrote a series of papers on the “Three Styles” outlining the assumptions of each paradigm. These had a formative effect on how I view the evolutionary social sciences. Third, I wrote a book chapter on the relationship between parenting and technology from an evolutionary perspective that was framed in a similar way. Fourth, I wrote a mini-review of the ecological factors influencing pairbond stability, which was fleshed out to become one of the sections of the current paper. Finally, I recently co-authored a paper on one aspect of pairbonding — the evolution of romantic love — with a PhD student at ANU.
The manuscript has been submitted to a peer-reviewed journal, and I have posted a pre-peer review version on the preprint server PsyArXiv:
Kushnick, G. (2022, June 4). Evolutionary Perspectives on Human Pairbonding: Reconciling the Major Paradigms. https://doi.org/10.31234/osf.io/vesgq.
In 2010, I was in Kabanjahe, the capital of the Karo regency of North Sumatra, Indonesia, studying marriage and baptism records at the area’s longest standing Catholic church. I sought data on the decline of impal marriage amongst the local Karo people. This was not my first trip to Taneh Karo. I had conducted a 12-month research project in two Karo villages for my PhD project.
There are two volcanoes jutting up from the plateau. The larger one, Gunung Sinabung, which I climbed on one of my earlier trips, had been dormant for 400 years. I rode my motorbike past one of the best vantage points when I noticed smoke issuing from the top of the mountain. I stopped in a village and the people there had noticed too. The place was buzzing with talk of the mountain and the ominous white cloud emanating from the puncak (peak).
Afternoon before first eruption of Sinabung (2010)
Just after midnight that evening, we felt a jarring of the earth, much like the frequent earthquakes I experienced growing up in the Los Angeles area. From the balcony of our rental home, we could see lava emitting from the Gunung Sinabung. Evacuees from near-by villages in the backs of pickup trucks and on motorbikes came flooding in. The next morning there were more eruptions that we could see clearly from Kabanjahe (see below). The eruptions have been occurring on-and-off continuously since that time.
View from my home in Kabanjahe on morning after first eruption (2010)
Evacuating the Volcano
The volcanic eruptions of Gunung Sinabung led to the evacuation of up to 17,000 people. By and large, these people are Karo farmers who are tied to the land on which they make their living. The land is equally important for Karo reproduction as it is for production. Some were able to return to their villages. Others lived in evacuation centres for extended periods. Others evacuated, returned, and re-evacuated. Some villages in the ‘red zone’ have been abandoned permanently and the people relocated to a new village called Siosar.
In 2014 I was awarded a Fulbright Scholars grant to continue my work on the decline of cousin marriage. During that five-month trip, interested in the living conditions of displaced Karo people, I visited evacuees that were staying in various evacuation centres. I was inspired to conduct research on the health of Gunung Sinabung evacuees.
To protect the identities of the participants of our study, we borrowed images of the volcano and its evacuees from the Getty collection (see below).
In 2017-18, I teamed up with a colleague at The Australian National University, Prof Alison Behie, who is an expert at the effects of natural disasters on maternal and child health, and the Chair of the Department of Anthropology at University of North Sumatra, Dr Fikarwin Zuska, who provided logistical support. We received generous funding from the ANU College of Arts and Social Sciences to support a round of fieldwork during which I would track down women who were pregnant during their evacuation. We wanted to compare their pregnancy outcomes with those of women who were pregnant at the same time but lived far enough away from the volcano to not have been evacuated.
The results of this study have been published in the American Journal of Human Biology. We found that the 97 women who were pregnant during their evacuation had an almost five-fold increase in the adjusted odds of having an early or preterm birth compared to the matching sample of 97 non-evacuee women. We also found that births to evacuee women were 1 cm shorter, when controlling for potential confounding factors, than births to non-evacuees.
Our study is important because it adds to the growing evidence that natural disasters lead to poor maternal/child health outcomes. It is one of the first to show early births and shorter, but not underweight, newborns. It is also the first to address evacuation from volcanoes. This is important because we are rapidly approaching a climate change tipping point for volcanic eruptions to become more common, and because volcanoes are location-specific and, thus, lead to increased vulnerability for those already vulnerable.
Kushnick G, Behie A, Zuska F (2021) Pregnancy outcomes among evacuees of the Sinabung volcano, 2010-2018 (North Sumatra, Indonesia): a matched cohort study. Am J Hum Biol, e23628. Link *
* The paper is behind a paywall, which means it is not viewable outside a subscribing library or without purchase. The publisher allows us to post a pre-peer review version of the paper on our personal website, so we have done this. Peer review added to the quality of the paper but the overall conclusions remained unchanged. Click here to see the free pre-peer review PDF.
Students enrolled in my course BIAN 2133/6133 (Human Reproductive Strategies) in Semester 2 of 2019 at The Australian National University wrote short topical articles about the evolution of human reproductive strategies and published them on a class Wiki site.
I’m very proud of them for doing this project. I hope you find the fruits of their labour useful and interesting!
Here’s a list of articles about the evolution of human mating:
Man holding a baby in a Karo village (picture taken by and copyright to Geoff Kushnick)
In one of the classes I teach at The Australian National University — “Evolution and Human Behaviour” (BIAN 3124) — I teach the students about the diverse evolutionary approaches that have been use to study human behaviour.
In my section on evolutionary psychology, I use a little experiment with the students to drive home some of the key concepts. I present them with a handful of questions about infidelity and we, invariably, find that the males in the class report much more concern about sexual infidelity than the females. The opposite is found for emotional infidelity. We, thus, replicate the finding of a sex difference touted by evolutionary psychology as one of their great successes (Buss 2018; Sagarin et al. 2012).
You see, the fitness payoff to males for investing in offspring is always tempered by the probability that they are being “tricked” into investing in an offspring that is not their own. Women don’t have to worry about this. One way for men to win this game is to adopt behaviours that serve to maximize the probability they have sired the offspring for which they are caring.
Jealousy is viewed as a strategy that can provide this result. Since this has been a recurring theme throughout human evolutionary history, evolutionary psychologists argue that you should see more intense jealousy evoked by sexual infidelity in men. In women, emotional jealousy is predicted to be more common. These patterns should hold up regardless of cultural background. It should be a universal.
On the face of it, the hypothesis has fared well when tested in a variety of settings, including cross-cultural ones.
As a human behavioural ecologist, I’m relatively uncomfortable with the concept of universality — and refer you to my paper “Why do the Karo Batak Prefer Women with Big Feet?” for more discussion (Kushnick 2013). People adapt to their environments via culture and biology, and since humans live in such a diverse range of socioecological settings I would expect human behaviour to be more complex than that. For most things, I expect humans to adopt flexible, conditional strategies.
According to pioneers of the field, Winterhalder and Smith (2000), said:
[Human behavioural ecology] usually frames the study of adaptive design in terms of decision rules, or conditional strategies: “In the context of X, do α; in context Y, switch to β.”
Why shouldn’t this logic apply to sexual jealousy as well? The benefits of acting jealously to stave off the chance of becoming a cuckold should vary with a number of socioenvironmental factors, not the least of which is the degree to which a man will provide investment (time, resources, etc) to his putative offspring. This is exactly the logic which led my colleague Brooke Scelza (an anthropologist at UCLA, who — like me — did her PhD under the supervision of the aforementioned Eric Alden Smith) to design a project whereby a number of us would conduct the experiment in different small-scale societies. Brooke takes you behind the scenes here.
I conducted the experiment in rural North Sumatra, Indonesia, amongst a group of people referred to as the Karo that I have been working with for over 10 years. The Karo are one of the so-called “Batak” groups who share some similarities, like a stated preferences for marriages with their matrilateral cross cousins — an aspect of their society that I have studied (Kushnick et al 2016).
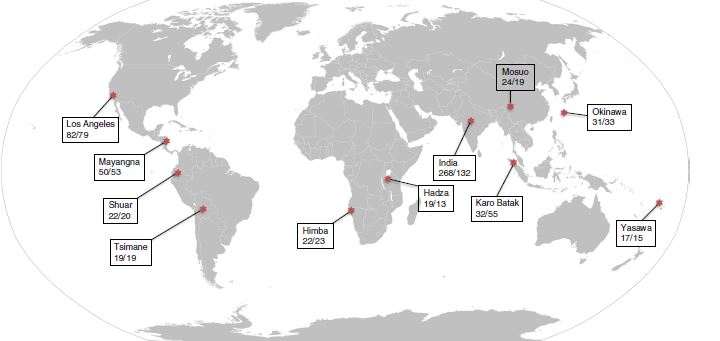
The results of this research, conducted with over 1000 subjects in 11 societies, have recently been published in Nature Human Behaviour (Scelza et al 2019). The article sits, unfortunately, behind a paywall, but the publisher has made a readable, but not downloadable version of the PDF available for free.
Map of field sites in Scelza et al (2019)
We found that jealous response, indeed, varied with the degree to which males were involved in parental care in those societies, as well as with the strictness of sociosexual norms, which are correlated with the male’s familial role in those societies.
We consider this a big win for human behavioural ecology, but a small step in the understanding of human nature and behaviour.
And Brooke was chuffed to see this comment from David Buss on Twitter:
This is such a cool paper. A great demonstration of how evolutionary hypotheses can predict cultural variation as well as universal sex differences…in this case in the powerful emotion of jealousy. https://t.co/fS3eMlhpqC
Buss DM (2018). Sexual and emotional infidelity: evolved gender differences in jealousy prove robust and replicable. Perspectives in Psychological Science, 13, 155-160.
Kushnick, G. (2013) Why do the Karo Batak prefer women with big feet? Flexible mate preferences and the notion that one size fits all. Human Nature, 24, 268-79. PDFLink
Kushnick G, Fessler DMT, Zuska F (2016) Disgust, gender, and social change: Testing alternative explanations for the decline of cousin marriage in Karo society. Human Nature, 27, 533-555. PDFLinkBlogData
Sagarin BJ, et al (2012). Sex differences in jealousy: a meta-analytic examination. Evolution and Human Behaviour, 33, 595-614.
Scelza BA, Prall S, Blumenfeld T, Crittenden A, Gurven M, Kline M, Koster J, Kushnick G, Mattison SM, Pillsworth E, Shenk M, Starkweather K, Stieglitz J, Sum, C-Y, Yamaguchi K, McElreath R (2019) Patterns of paternal investment explain cross-cultural variance in jealous response. Nature Human Behaviour. PDFLink
Francis Galton pioneered the concept of eugenics in this lab in London in the late 19th century. (Flickr/Science Museum London)
Eugenics — the science of improving the race —was a powerful influence on the development of Western civilisation in the first half of the twentieth century. And Melbourne’s elite were among its chief proponents.
In this period all the institutions and practices of modern societies came into being and eugenics played an important role in moulding them.
As the home of the Australian federal government in the early decades of the twentieth century, Melbourne was the ideal place for activists wishing to pursue a national eugenic agenda.
The role of the University of Melbourne
An important leader of this loose alignment of like-thinking middle class academics and doctors was the Professor of Anatomy at Melbourne University from 1903 to 1929, Richard Berry. His influence extended beyond the university, which still has a building bearing his name, to some of the most important members of the city’s society.
Although there was a short-lived Eugenics Education Society, until the founding of the Eugenics Society of Victoria in 1936 eugenicists operated primarily as a pressure group within the university, the education department and various government agencies and committees.
The bill aimed to institutionalise and potentially sterilise a significant proportion of the population – those seen as inefficient. Included in the group were slum dwellers, homosexuals, prostitutes, alcoholics, as well as those with small heads and with low IQs. The Aboriginal population was also seen to fall within this group.
The first two attempts to enact the bills failed not due to any significant opposition but rather because of the unstable political climate and the fall of governments.
The third in 1939 was passed unanimously, but not enacted in the first instance because of the outbreak of war and, later, due to the embarrassment of the Holocaust.
Other state parliaments were inspired to also institute such legislation by Berry’s many town hall lectures across the nation.
Important national Royal Commissions in the 1920s also recommended a range of eugenic reforms including measures relating to child endowment, marriage laws and pensions.
National survey
Perhaps the culmination of all this activity was the commissioning of a national survey of mental deficiency by the Federal Minister for health, Sir Neville Howse, in 1928.
It was carried out by Berry’s colleague, the Chief Inspector for the Insane in Victorian William Ernest Jones. In it, he claimed that the statistics collected showed the incidence of mental deficiency was rising, mainly due to genetics, and was more often found in the working class. He concluded that it required urgent government action along the lines previously championed by Berry. It was tabled before parliament and created a sensation in the press.
Little happened, however, as the government fell and the Great Depression hit the nation. The Director of the Department of Health, John Cumpston, claimed that the dire financial situation destroyed any chance of such a reform.
Eugenics in education
Another important influence of eugenic thinking was found in the development of post-primary education in Victoria.
The most important educationalists involved in the radical developments in the development of secondary and technical schools in Victoria were either active in eugenic circles or closely associated with Berry.
Perhaps the most influential, the first director of education, Frank Tate, was associated on most important government bodies with Berry and strongly supported his research on head size and, on occasions, introduced his public lectures.
Others, such as the first Director of the Carnegie funded Australian Council for Educational Research, Kenneth Cunningham, as well as one of the most significant early psychologists, Chris McRae, published research claiming to show that working class children were unfit for academic secondary education and the university study that it led to.
McRae replicated in Melbourne suburbs research carried out in a variety of different socio-economic suburbs of London. He subsequently reported in the Victorian Education Gazette (sent out to every state school primary teacher) that those in schools in poorer suburbs “will never go to university and should not follow the same curriculum … people live in slums because they are mentally deficient and not vice-versa”.
As a consequence, in this period the Victorian Education Department set up technical schools in the poorer suburbs of Melbourne with just a few academic high schools.
In comparison, in New South Wales the Director of Education, Peter Board, vigorously opposed such thinking and championed higher education opportunity for all. Many more state school children in New South Wales were given an academic secondary education and went on to university.
The spread of the movement
Richard Berry returned to England in 1929 but
others took up the mantle, founding the Eugenics Society of Victoria.
Its membership read like a who’s who of Melbourne’s elite including the Chief Executive Officer of the Council for Scientific and Industrial Research — the precursor to the CSIRO, the Vice-Chancellor of the University of Melbourne, the President of the Royal College of Physicians and the Chief Justice of the Supreme Court of Victoria.
Although the aims of the society included supporting the sterilisation of mental defectives, more and more they were involved in environmental reforms (such as slum clearance) and the birth control movement.
Berry’s legacy
In Britain Richard Berry continued to preach his uncompromising theory of “rotten heredity”. In 1934 he would argue that to eliminate mental deficiency would require the sterilisation of twenty-five per cent of the population. At the same time he also advocated the “kindly euthanasia” of the unfit.
Although Melbourne may wish to forget its dark past, the powerful leaders of the eugenics movement once controlled the city, and their beliefs influenced a generation.
Parenting and technology interact in many ways. As a sampling of these interactions, take the illustrations in Figure 1 of my soon-to-be-published chapter titled “The Cradle of Humankind: Evolutionary Approaches to Technology and Parenting” in the upcoming book The Oxford Handbook of Evolutionary Psychology of Parenting. The thesis of the chapter is that evolutionary theory has helped — or, in some cases, can help — us to understand of the relationship between parenting and technology.
Figure 1. Technology as always been an important driver of offspring-directed parental behaviour and beliefs, and vice versa. Pictured here are some examples: (A) terracotta infant-feeding vessel from southern Italy (4th Century BC); ; (B) advertisement for a baby cage used to get fresh air for children in crowded cities (early 20th century); (C) woman getting a fetal ultrasound in a rural clinic in Brazil; (D) ingenious contraption used by a Karo mother in rural Indonesia to keep a baby safe and occupied with a chair, umbrella, and mobile phone while she tends to a tomato garden; (E) woman with her baby slung on her back using a water pump in Ghana; and, (F) Sami woman carrying a child in a Komse, or child carrier, in Lapland, Sweden (ca. 1880). Copyright information for images: (A) photograph taken by author from ANU Classics Museum, Canberra; (B) public domain image taken from Fischer (1905); (C) Agencia de Noticias do Acre, Creative Common CC BY 2.0; (D) photograph taken by author; (E) USAID, public domain; and, (F) public domain image from 1880.
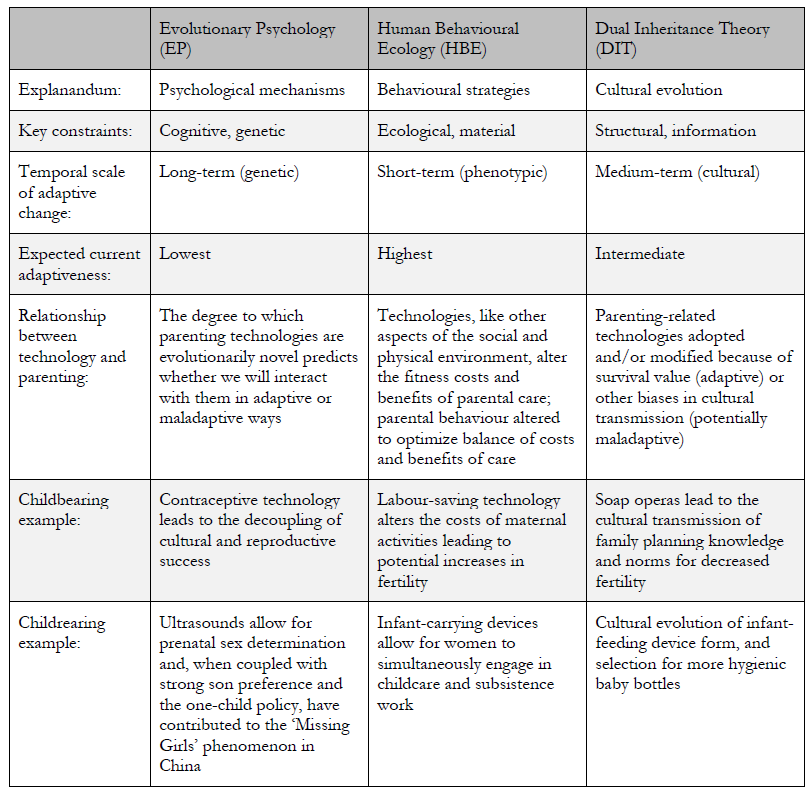
Now, I had to start the chapter by sorting out that parenting can mean both childbearing (producing offspring) and childrearing (raising offspring). Further, I wanted my account to include the full range of the most frequently adopted evolutionary approaches to understanding human behaviour: evolutionary psychology, human behavioural ecology, and dual inheritance theory. With this framing, I chose six examples as illustrated with Table 1 from my chapter:
Table 1. Evolutionary approaches to the study of human behaviour: the ‘three styles’ framework (adapted from Smith 2000: 34).
If that sounds interesting to you, please check out the preprint of my chapter, which I am allowed to provide under Oxford University Press’s Author Re-Use and Self-Archiving policy. The book is slated for publication in the 4th quarter of 2018. I will update this post with a link once that occurs.
Kushnick G (in press) The cradle of humankind: Evolutionary approaches to technology and parenting. In: Weekes-Shackelford VA, Shackelford TK (eds.), The Oxford Handbook of Evolutionary Psychology and Parenting. Oxford University Press. (To appear in 2019).
Teaching is an important skill to develop when you are still a PhD student, as many academic job opportunities requires some degree of teaching experience.
But, how can one get teaching experience when opportunities are scarce? Unfortunately, I don’t have a definitive answer. I was lucky to get lots of teaching experience as a PhD student. What I can offer some advice for PhD students regarding teaching and being a teaching assistant (or Tutor in Australian academia).
The following advice is drawn from a handout I developed to pass out to PhD students attending my lecture on building a teaching portfolio that I gave at the University of Washington during my time as a Lecturer there between 2007 and 2014. It was part of the necessary training that TAs had to undergo before starting:
TAing (Tutoring) and Teaching are Different but the Same: With TAing (or tutoring), you are following a curriculum set by the instructor; with teaching, you are following your own This doesn’t mean, as a TA, you’re required to suppress your individuality. It just means that you need to teach the material the instructor deems important. This is actually a good thing: I’ve found that the best TAs are creative (within an established set of boundaries). Hey, and if you can perfect that skill, you will be a very attractive hire both within academia and beyond it! With both, you are one of the key elements of the learning experience for the students in your class. When teaching or TAing, I believe it’s equally important to take pride in your performance (e.g., by being familiar with the material, preparing ahead of time, acting professionally, etc.) and to develop a sincere interest in whether the students learn (e.g., by listening sometimes instead of talking all the time, making yourself available, etc). Of course, this is a balancing act since teaching is only one part of your academic career, and your academic career is only one part of your life.
TAing (Tutoring) is Good, but Teaching is Better: At the bare minimum, you’ll have to TA at least once to get through the PhD program (in most programs, at least). Chances are you’ll do it more than If you get a chance to teach a class—meaning act as the actual instructor of a class—take it! Some of the benefits include: (a) a taste of greater responsibility (let’s face it, as a TA, we have a lot of responsibility, but the ultimate responsibility—if something goes wrong, for instance—is in the hands of the instructor); (b) a chance to infuse the lesson plan with a larger dose of your personality and interests; (c) having a complete class ready to go when you’re called upon to do it professionally—which potentially frees a lot of time to focus on other important things (e.g., it could mean you’ll have more time to write and less time preparing for class when you get an academic job); and, (d) it looks great on your CV. I didn’t teach as a grad student (only TA’d). I thought it better to push toward a completed dissertation without distraction. Painfully unrealistic and wrong at worst. Short sighted at best.
Teaching= Learning: I once ran into a student in the library, and was dismayed by what I heard: “Dr Kushnick, what are you doing in the library? I didn’t know teachers use the library. What a bummer that you still have to read.” Teaching (or TAing) provides a great opportunity to learn, and I suggest you learn as much as you can. Use your preparation time as a chance to learn something new. Read about how to be an effective teacher. Be careful though. Some of what is out there is specific to teaching at a specific school and since every school has a different teaching (and TAing) culture and social structure, some of it won’t be all that valuable. The useful stuff, in my opinion, is the stuff that’s simultaneously both general and specific—general enough to apply to teaching anywhere, but specific in that it provides advice about specific things you might do to improve your effectiveness (see the list from Webb’s article in the sidebar is a good example). The stuff that applies to teaching at a particular institution is useful too (if you’re teaching at that institution).
Manage Your Portfolio: I’ve applied for more academic jobs than I’m willing to admit, and I count myself as lucky to have had this Lectureship for the past few I believe I’m qualified to make generalizations about what you’ll find in the job ads; less qualified to make statements about how to get the jobs being advertised. More than half of the available jobs I’ve seen ask for a detailed statement of your teaching interests and experience, and documentation of your “commitment to teaching excellence.” Usually, you’re asked to include this information as part of the application letter. Sometimes, you’re asked to send a separate teaching statement or mini‐portfolio. Other times, especially when applying to large research institutions, you’re asked for less information about your teaching. Whether the job you’ll be applying for asks for a lot or a little information, you’re better off if you’ve been keeping a portfolio of teaching materials that you can pull from to build your application. This might include: syllabi from courses you’ve taught or TA’d; evaluations from students or instructors; video or audio recordings of you in the classroom; notes regarding your teaching philosophy, if not a draft of an actual statement; etc, etc…
Twelve Easy Steps to Becoming an Effective Teaching Assistant
By Derek Webb from (2005) Political Science and Politics, v.38, pp. 757‐761.
Derek Webb was a PhD Candidate at when he published this. He was the winner of the 2003 Outstanding Graduate Student Teaching Assistant at Notre Dame University. Here are his steps to being a great Teaching Assistant for those who find the opportunity:
Be yourself.
Be available.
Be organized.
Learn your students’ names ASAP.
The three goals of discussion section: Nuts and bolts, challenge and excitement, fun and games.
Provide a handout or or agenda.
Provide a mini‐lecture.
Provide an opportunity for students to ask questions.
Evolutionary anthropologist with expertise in human behavioural ecology. Research interests include human reproductive strategies, evolution of social norms and institutions, quantitative methods and analysis, and the peoples of SE and the Pacific.













 Teaching is an important skill to develop when you are still a PhD student, as many academic job opportunities requires some degree of teaching experience.
Teaching is an important skill to develop when you are still a PhD student, as many academic job opportunities requires some degree of teaching experience.

